Frøy Gudbrandsen har skrivi en veldig god kommentar, «De usikre 22», om hvor svakt grunnlag som finnes i valgundersøkelsene for å si noe om velgeroverganger i småpartier. Hun skriver at de som står bak valgundersøkelsene underkommuniserer hvor stor usikkerheta er. Det er jeg heilt enig i. Jeg har tidligere tatt opp dette i SV-interne fora, og tenkte at jeg kunne dele noen av de analysene jeg har gjort, siden saka er blitt aktuell. Ikke minst er dette interessant og relevant også for de andre små partia. De eineste partia som får noe ut av valgundersøkelsene på dette området er egentlig Arbeiderpartiet og Høyre.
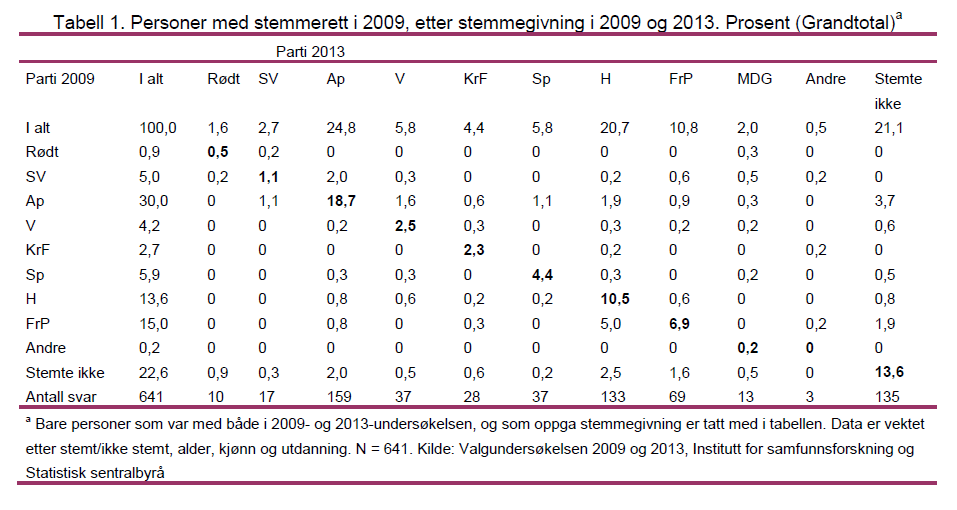
I motsetning til Gudbrandsens kommentar har ikke jeg fokusert på hva SVs (eller andre partiers) velgere i 2009 stemte denne gangen, men hva de som stemte SV (eller andre partier) i 2013 stemte i 2009. La oss først begynne med å se på hvordan data presenteres i den forstudien til Valgundersøkelsen 2013 dette er snakk om, notatet «Velgervandringer og valgdeltakelse ved stortingsvalget 2013» (.pdf). Figur 1 viser dette. La oss deretter multiplisere de andelene som kommer fram i denne tabellen, med det antallet respondenter som ligger til grunn. Resultatet fra denne multiplikasjonen er vist i figur 2.
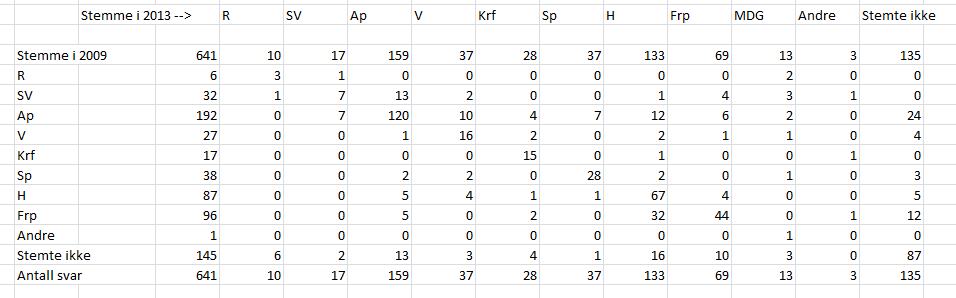
På dette punktet vil det begynne å skurre for de fleste som har et grunnkurs i statistikk. Antallet respondenter er i mange tilfeller svært, svært lavt. En «overgang» på 0,2 prosentpoeng av velgermassen viser seg å være en eneste person. Det totale antallet respondenter for alle partier unntatt Arbeiderpartiet, Høyre og Fremskrittspartiet er under 40. Det er klart at dette får til dels store konsekvenser for hvor bastant man kan være.
Statistikken som ligger til grunn her er temmelig enkel om man har tatt et universitetskurs i statistikk (hvis ikke er det sjølsagt ganske komplisert). Jeg har gjort rede for den i et tidligere innlegg om meiningsmålinger. En kortversjon som forklarer de tekniske sidene ved dette følger i de neste avsnitta. Som det går fram i det gamle innlegget mitt, er det lett å beregne usikkerheta i sånne anslag. Den vanlige måten å gjøre det på er i form av konfindensintervall. Som regel bruker man konfidensintervall, og framgansmåten er godt beskrivi hos Stattrek.
Med utgangspunkt i sentralgrenseteoremet legger man til grunn at konfidensintervallet kan finnes ved å multiplisere det empiriske standardavviket s = √(p(1-p) / n) (der p er andelen i utvalget og n er størrelsen på utvalget) med en bestemt verdi. Denne verdien tilsvarer det antallet standardavvik, z(α), som man må legge til eller trekke fra gjennomsnittet av alle utvalg for å finne en gitt andel, α, av utvalga – bare på grunn av tilfeldigheter. Som regel beskriver man konfidensintervalla med verdien 1-α %, altså den andelen av anslaga som vil ligge innafor konfidensgrensene. Den vanligste verdien av α er 0,05, som altså gir 95 % konfidensintervall. Skjematisk kan vi skrive konfidensintervallet sånn:
p ± (s · z(α))
Det mange ikke tar hensyn til er at hvor mange konfidensintervall du vil oppgi påvirker størrelsen på z. Denne verdien følger av den kumulative sannsynlighetsfunksjonen til normalfordelinga. Hvis du ikke har laga ei begrunna hypotese om at utvalget ditt har en større eller mindre andel enn populasjonen som heilhet må du teste «tosidig» og bruke αkorrigert = α/2. Skal du oppgi ett konfidensintervall, og ønsker å bruke 95 % konfidensnivå – som altså betyr at du tolererer å oppgi et galt intervall i ett av 20 tilfeller – får du altså en z-verdi på 1,96 (ikke 1,65). Skal du oppgi meir enn ett konfidensintervall, auker du antall muligheter for å havne utafor de 95 % du har satt opp som krav. For at det ikke skal være meir enn 5 % sannsynlighet for at noen av konfidensintervalla dine skal være gale, må du derfor ha en annen z-verdi. Den vanligste måten å gjøre dette på er ved hjelp av en Bonferroni-korreksjon. Da får du αkorrigert = α/(2 · n).
Hvis man skal oppgi svært mange konfidensintervall, er det klart at effekten av dette kan bli dramatisk. Men den er også merkbar for bare et ganske lite antall. Referanseramma i Frøy Gudbrandsens tekst er jo f.eks. ikke et enslig anslag på SVs velgerlojalitet, men ei sammenligning av velgerlojaliteten til alle svaralternativene i undersøkelsen. Siden det er 10 svaralternativer, får vil αkorrigert = α/(2 · 10), som gir en z-verdi på ca. 2,81, og konfidensintervallet for SVs velgerlojalitet blir dermed 22 ± 20 %, eller for å skrive det på en annen måte 1 – 42 %. Verdien «1» dukker opp her fordi 22 er avrunda fra 21,875 og 20 er avrunda fra 20,4622. Det er altså ikke langt unna at usikkerheta er så stor at det bare er en avrundingsfeil som skiller anslaget på velgerlojaliteten fra 0 (og statistisk meiningslaushet).
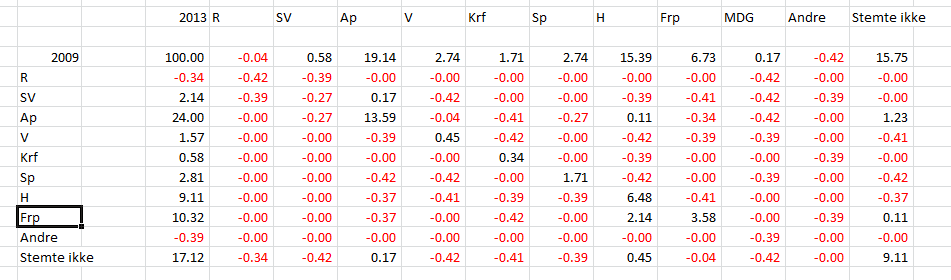
For å illustrere hvor galt dette kan gå, kan vi sette opp heile velgerovergangstablået fra figur 1, der jeg har satt opp nedre grense for størrelsen på konfidensintervallet, etter å ha korrigert for det totale antallet konfidensintervall (n=110). Dersom denne grensa er lavere enn 0, er tallet vist i rødt. Jeg gjør oppmerksom på at øverste rad og venstre kolonne, altså totalene, ikke er tatt med i korreksjonen. Figur 3 viser resultatet. Ei uttømmende liste over ting valgundersøkelsen sier heilt sikkert på dette området blir da:
- Minst 0,17 %-poeng av oppslutninga til Arbeiderpartiet kommer fra tidligere SV-velgere.
- Minst 13,9 %-poeng av oppslutninga til Arbeiderpartiet kommer fra folk som også stemte Ap sist.
- Minst 0,17 %-poeng av oppslutninga til Arbeiderpartiet kommer fra folk som ikke stemte i 2009.
- At henholdsvis minst 0,45; 0,34; 1,71 og 3,58 %-poeng av oppslutninga til Venstre, Kristelig folkeparti, Senterpartiet og Frp kommer fra folk som stemte på disse partia også i 2009.
- Minst 0,11; 6,48; 2,14 og 0,45 %-poeng av oppslutninga til Høyre kom fra folk som tidligere henholdsvis har stemt Ap, Høyre, Frp eller ikke har stemt.
- At minst 1.23 %-poeng av befolkningsandelen som ikke stemte i 2013 stemte Arbeiderpartiet i 2009, og minst 0,11 %-poeng Frp, og dessuten at minst 9.11 %-poeng av denne befolkningsandelen heller ikke stemte ved 2009-valget.
Det numerisk sett sterkeste funnet er altså at de som ikke stemmer fortsetter å ikke stemme. Bortsett fra folk som fortsetter å stemme på de partiene de stemte på sist er det numerisk sett sterkeste funnet velgerovergangen fra Frp til Høyre. Som Frøy Gudbrandsen peiker på: Hvordan man leser statistikken påvirker i stor grad hvilke historie man lager. Det er temmelig interessant å merke seg at de historiene som skaper størst oppmerksomhet på ingen måte er det historiene som har sterkest støtte i undersøkelsen.